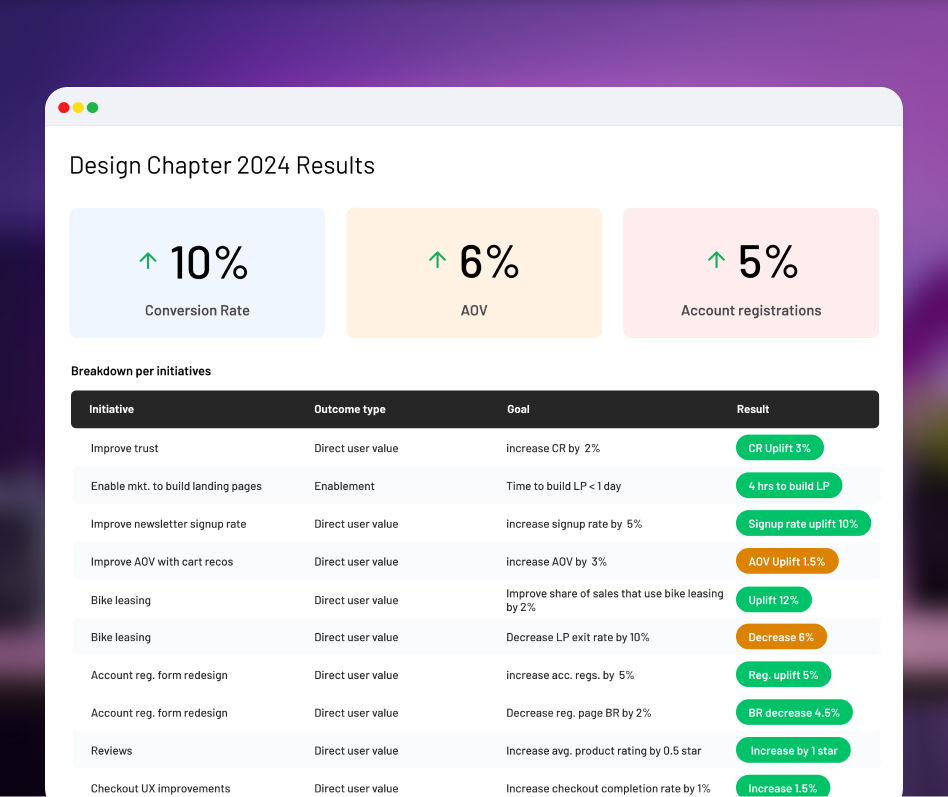
From voice notes to interview-winning portfolios: building the AI pipeline behind CraftWins
Built CraftWins from zero to alpha in one month: a five-model AI pipeline that transforms voice notes and screenshots into portfolio-ready case studies, now used by early adopters in active job searches.

TL;DR
- Designers lose jobs they deserve because translating past work into polished case studies takes too long.
- I built CraftWins in one month as a solo project: a multi-model pipeline that generates structured case studies from raw input.
- I chose five models over one, matching each stage to the best model for the job.
- Over half of early users now have a CraftWins case study on their website for active job searches.
- User research after launch revealed that the output was technically strong but didn't make users feel like winners, leading to a new direction.
Designers keep losing out on roles they are qualified for
Most designers I spoke to had the same story: strong work, weak portfolio. Not because they lacked skill, but because translating project experience into a compelling case study is genuinely hard. It requires writing ability, narrative instinct, and hours of focused effort, often while unemployed and under financial pressure. The result is that talented people lose roles they deserve.
Existing tools don't solve this. Generic AI writing tools produce templated output that hiring managers see through immediately. Portfolio builders handle layout but not narrative. No tool understands what a hiring manager actually looks for in a case study and helps a designer tell that story from their raw project notes.
A tool that turns messy project notes into interview winning case studies.
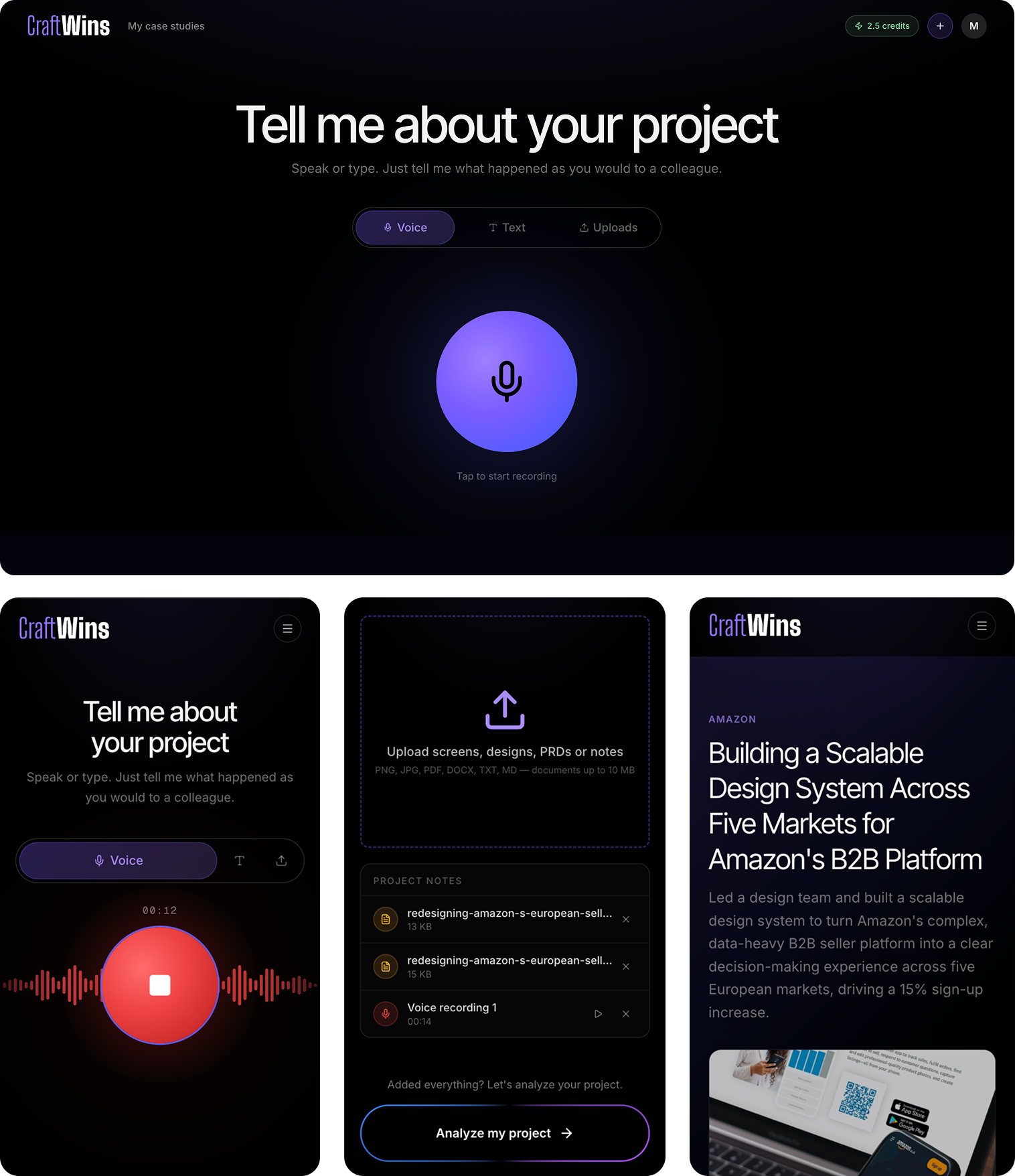
CraftWins is an AI tool that helps designers and PMs create portfolio case studies from voice notes, screenshots, and documents. The experience is simple: a user records a voice note, uploads some screenshots, and gets a structured case study in minutes. What makes that possible is the system underneath.
- Transcription: gpt-4o-mini-transcribe handles messy voice notes with natural speech patterns and accents
- Document extraction: gpt-4o-mini for PDFs, mammoth for DOCX, plain pass-through for text
- Image analysis: gpt-4o generates detailed descriptions so the writing model gets visual context as text
- Analysis and clarification: gpt-5-mini evaluates input quality across seven signals and generates targeted questions
- Case study generation: Claude Opus produces structured JSON that maps directly to UI components
A second key decision was outputting structured JSON instead of a formatted document. The AI returns data that maps directly to UI components, giving me control over rendering, editing, and future layout flexibility.
A pipeline where each model does what it is best at
I faced a fundamental architecture decision early: use a single large model for everything, or build a pipeline where each stage uses the model best suited for the job.
I chose the multi-model pipeline. Transcription of messy voice notes needed a model good at natural speech. Analyzing input and generating clarification questions needed strong reasoning at low latency. Case study writing needed the best long-form prose model available (Claude Opus). Image understanding needed to happen separately so the writing model received visual context as text.
What I gave up was simplicity. Five models means five sets of prompts, five failure modes, and a more complex pipeline. But mediocre output at the step that matters most was not an acceptable trade-off.
The output was good. It just didn't make users feel like winners.
After shipping, I ran in-depth interviews with alpha users. The signal was consistent and surprising. Every user praised the output quality. Most used the generated case study directly.
But something was off. The case studies followed every best practice you'd find in a Medium article. Structurally correct. But users didn't feel like winners reading about their own work. In the stress of a job search, that's exactly what they needed, and the output wasn't delivering it.
I also built an evaluation framework scoring output across seven dimensions to systematically improve quality. This is how I caught the comprehensiveness trap (the model honoring all user input instead of curating it) and collaboration sections drifting into awards-speech language. The output was technically correct but not emotionally right.
This taught me something I keep coming back to: AI can build a good product fast. Making the user of that product actually feel good is still the human's job.
Closing the gaps users showed me
User research also revealed a practical pattern: every user left the product after generation. One to edit and refine. One to publish. The job was never fully done inside CraftWins.
This shaped the roadmap directly:
- Wynn: a conversational editing agent that evaluates the case study against one seniority level above the user's inferred level, surfaces the most impactful gaps, and helps fix them through conversation. Two-model architecture: gpt-5-mini for coaching dialogue, Claude Sonnet for section rewrites, all behind a single persona. The design principle: make the user feel like a winner. Not fixed, not corrected, but ready.
- Public portfolio pages: a shareable page at /username so users don't have to leave CraftWins to publish their work.
Early validation from real users in real job searches
Over half of early users have a CraftWins case study on their personal website, used in active job searches. This was not prompted or incentivized. They chose to use the output because it was good enough.
“I just threw in some rough voice notes and a couple of screenshots, not expecting much. What came back actually sounded like me on a good day. I kept reading it thinking okay, where's the catch.”
John, Interaction Designer
“The questions before generating were my favourite part. It asked me about things I completely forgot about, details from months ago that ended up making the whole story click.”
Peter, Product Manager
“I've been putting off my portfolio for weeks because I just couldn't start. I gave it my messy notes and honestly, 20 minutes later I had something I was proud to send out. That's never happened before.”
Julia, UX Designer
The evaluation framework has driven measurable prompt improvements, catching quality issues before they reach users. And user research directly shaped every prioritization decision since launch.
This case study was written with CraftWins.